Ollama: Tu IA privada y gratuita similar a «ChatGPT»
Creo que a estas alturas y más si estás leyendo esta entrada, conoces al menos lo básico de la inteligencia artificial, mas concretamente los modelos LLM o como mucha gente conoce por ser uno de los primeros servicios en darse a conocer de forma masiva «ChatGPT».
Estos modelos de lenguaje mediante inteligencia artificial, no sólo pueden seguir conversaciones de forma totalmente natural, si no que se han convertido en el aliado perfecto a la hora de desempeñar nuestras tareas o requerir ayuda en alguna ocasión.
Hoy vengo a hablar de Ollama, un proyecto de código abierto que realmente me ha llamado la atención, ya que no sólo simplifica el uso de la IA en cualquier plataforma, si no que está diseñado de una forma totalmente personalizable y extensible, además de trabajar de forma privada y totalmente gratuita.
¿Qué es Ollama?
Ollama es una aplicación capaz de cargar modelos largos de lenguaje (LLM) que ofrece una interacción mediante CLI, pero su verdadero potencial es su uso mediante API.
Al ofrecer una API, la aplicación es básicamente agnóstica, cumple su función principal y nos deja abierto un gran abanico de posibilidades, por ejemplo nos permite conectarla y utilizar cualquier interfaz de nuestra preferencia, pero no sólo eso, si no que podemos conectarla con otros proyectos LLM como LangChain y expandir aún más su potencial, pero hoy vamos a centrarnos en lo básico y dejaré para más adelante sus diferentes extensiones.
Además y también muy importante, es que al ser privado y ejecutarse solo en nuestros equipos, podemos tener la confianza de proporcionarle los datos que queramos, ya que estos no se compartirán con ninguna empresa ni servidores de terceros.
Instalación de Ollama
Ollama ya pone a nuestra disposición diferentes instaladores dependiendo de nuestra plataforma, a día de hoy ya es compatible con Windows, Linux y Mac, y admite tarjetas Nvidia o AMD, por lo que en términos de compatibilidad es bastante completo, simplemente faltaría el soporte de las Intel ARC.
Para instalarlo, simplemente nos dirigimos a su web oficial presionamos el botón de «Download» y seleccionamos el instalador correspondiente a nuestro sistema operativo, no voy a hacer una guía de esto porque el equipo de Ollama ya se ha encargado de hacer la instalación sencilla para todo tipo de usuario.
Cambio de directorio de archivos de Ollama
Bien, antes de comenzar a trabajar con Ollama, es posible que te interese ajustar donde va a escribir todos los archivos, ya que los modelos, suelen ser pesados y posiblemente no te interese tenerlos en tu disco duro del sistema, si solo tienes un disco o te da igual que guarde todo en el disco del sistema, puedes dejar la ruta por defecto y saltarte completamente este paso.
Para cambiar el directorio donde Ollama guarda sus archivos, debemos hacerlo a través de la variable del entorno «OLLAMA_MODELS», en mi caso voy a enviar todos los archivos a mi disco duro secundario D:, por lo tanto el valor de la variable quedaría así:
D:\IAs\ollama\models
Servicio accesible en red
Este paso es sólo para el que quiera tener el servidor Ollama accesible en red, si vas a usarlo sólo en el mismo equipo donde ejecutas ollama o vas a instalar alguna interfaz en el mismo, puedes saltarte completamente este paso.
Ollama nos permite abrir sus conexiones más allá de nuestro propio PC, lo cual nos permite conectar diferentes dispositivos a nuestro servidor Ollama a través de nuestra red local, para abrir las conexiones, debemos establecer 2 variables de entorno más.
En primer lugar necesitamos establecer la variable «OLLAMA_HOST» está variable es la que va a indicar en que direcciones IP va a escuchar nuestro servidor, si tenemos una tarjeta dedicada a nuestra LAN podemos utilizar su IP, o si queremos que escuche en todas las direcciones la tenemos que establecer en:
0.0.0.0
La otra variable que debemos ajustar, es «OLLAMA_ORIGINS» esto aporta un poco más de seguridad a nuestro servidor ya que habilita CORS y deniega las peticiones desde las IP’s o URL’s que no se encuentran en el listado.
En mi caso, voy a conectarme y cargar la interfaz desde el servidor de mi red (192.168.1.100) y el dominio local «https://server.home», por lo que la variable de entorno debería de tener este valor:
http://192.168.1.100,https://server.home
Podemos agregar todas las que necesitemos simplemente separando por comas y no agregando espacios.
Uso mediante CLI
Para ejecutar Ollama mediante la consola de comandos, tenemos que especificarle un modelo.
Ollama pone a nuestra disposición los modelos más conocidos a través de su librería, en este ejemplo vamos a utilizar «Mistral7B» por lo que para ejecutar Ollama y descargar el modelo simplemente debemos introducir el siguiente comando en la consola:
ollama run mistral
Esta descarga sólo se realizará cuando los modelos no se encuentren previamente descargados, una vez ya están descargados su inicio será mucho más rápido, una vez esté listo nos encontraremos una pantalla como esta:
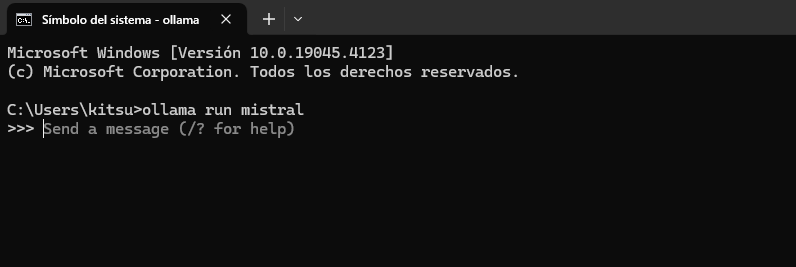
Donde ya simplemente podremos interactuar con la IA escribiendo lo que queramos, es importante que si usamos un texto muy largo o varias lineas de texto, lo comencemos y lo finalizemos con tres comillas dobles, ejemplo:
"""Necesito crear un titulo optimizado para SEO que incluya las siguientes palabras: ejemplo, ollama, texto, multilinea"""
Pero este tan sólo es un uso simple de la aplicación, el uso mediante API y el poder conectarlo a una interfaz es el que realmente nos interesa, por lo que no voy a profundizar mucho más aquí.
Respecto a los recursos, no te preocupes por ellos, ya que ollama descargará de la memoria el modelo a los 5 minutos de la última petición por defecto, obviamente la velocidad de respuesta y los modelos que podremos cargar dependerán de las prestaciones que tenga el PC.
Uso mediante API
El uso mediante API es realmente donde ollama nos va a resultar mas atractivo, dispone de una API bastante completa que nos permitirá conectarlo a cualquier interfaz, ya sea OpenWebUI, SillyTavern… además de poder realizar integraciones propias, voy a poner un ejemplo de una petición para generar una repuesta a tiempo real (stream) mediante Axios:
import Axios from 'axios';
const message = "Necesito crear un titulo optimizado para SEO que incluya las siguientes palabras: ejemplo, ollama, texto, multilinea";
const model = "mistral:latest";
const axios = Axios.create({
timeout: 0,
});
var request = await axios({
method: 'POST',
url: 'http://127.0.0.1:11434/api/generate',
data: {
"model": model,
"prompt": message,
"stream": true
},
responseType: 'stream'
});
const stream = request.data;
stream.on('data', chunk => {
chunk = chunk.toString()
console.log(chunk)
});
Como puedes ver Ollama es realmente útil, ya que no sólo vamos a poder conectarlo con muchos proyectos de código abierto, si no que podemos crear cualquier script o programa personalizado que haga uso de la IA cuando lo requiramos.
Esta entrada es la introducción de una serie de tutoriales sobre Ollama, por lo que te recomiendo seguir la etiqueta para explotar todo su potencial y si te gusta la Inteligencia artificial, he creado una categoría para todas las publicaciones relacionadas con la IA.
En el próximo tutorial, veremos como se instala la interfaz web OpenWebUI que nos facilita el uso de Ollama así como nos ofrece diversas funciones extras.