Cómo funciona Stable Diffusion
Antes de comenzar con Stable Diffusion, es necesario conocer como esta IA es capaz de generar las imágenes, ya que nos servirá para comprender mejor el uso de cada parámetro y/o herramienta.
Esta explicación es básica, resumida y enfocada al usuario común, existe información más detallada y específica que esta, mi objetivo aquí es solo ofrecer el conocimiento básico y simple para comenzar a publicar diferentes tutoriales sobre esta inteligencia artificial.
Los modelos Diffusion, se entrenan descomponiendo las imágenes en ruido y almacenando detalles relacionados con el prompt, después, vuelve a tratar de componerla usando sólo el ruido y el prompt con el fin de volver a obtener un resultado bastante similar a la imagen inicial.
Nubes de ruido y pasos
Cuando nuestra imagen comienza a generarse, comienza por una imagen aleatoria donde sólo hay ruido y a través de los pasos va eliminando ese ruido con el fin de adaptarse a nuestro prompt y nuestros parámetros.
Este es un ejemplo de los pasos que va realizando para componer una imagen con el prompt «A cute fox girl»:

Como se vé en la imagen anterior, la imagen comienza por un ruido muy difuso y poco a poco según va aumentando el número de pasos se vuelve más perceptible y se van agregando más detalles.
El número de pasos depende del tipo de imagen (una imagen estilo anime necesita menos pasos que una foto-realista), también del número de detalles y elementos que la componen, por lo que hay que tenerlo en cuenta.

Realizar más pasos de los necesarios comenzará a realizar efectos negativos sobre nuestra imagen, ya que tratar de eliminar el ruido más allá de lo necesario, sólo comenzará a producir errores y deformaciones en la misma, como esta imagen generada a 150 pasos y el resultado es bastante positivo frente a lo que me esperaba, pero aún así podemos denotar una perdida de calidad importante en la imagen, si la comparamos por ejemplo con la de 30 pasos.
Es importante saber que toda la imagen se compondrá en cada paso transformando este ruido, ya que todos los parámetros y herramientas que utilicemos, harán referencia al número de pasos y actuarán sobre el ruido en cuestión y no sobre la imagen ya finalizada.
Ruido inicial y semilla
El ruido generado en el primer paso es totalmente aleatorio y no será afectado ni por nuestro prompt ni por ningún parámetro salvo la semilla (seed), la semilla no es mas que eso, el hash que toma el ruido inicial antes de comenzar a componer nuestra imagen.
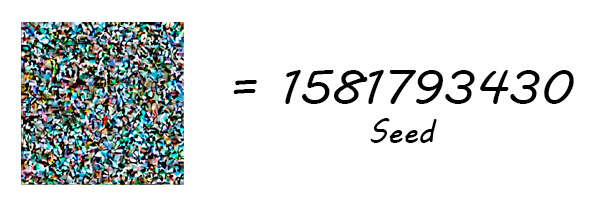
Es por esto que aunque proporcionemos el mismo prompt y los mismos parámetros, siempre nos va a generar una imagen distinta, a no ser que utilicemos el mismo seed que se empleó anteriormente.
También es importante mencionar que la semilla va ligada al tamaño de la imagen, si lo modificamos, ya no nos generará una imagen exacta tampoco, ya que al cambiar el tamaño, varía también el tamaño la nube de ruido y por tanto la semilla no generará exactamente los mismos píxeles que en el tamaño anterior.
Sin embargo, aunque modifiquemos el tamaño, utilizar la misma semilla nos puede resultar útil, ya que a pesar de que no va a generar la misma imagen exactamente, si que fijará patrones similares y hará que al menos esta se parezca.
Como detalle adicional, existe un parámetro de configuración llamado «Clip Skip» que nos permite saltarnos los primeros pasos de ruido.
Para imágenes tipo anime, se suele establecer este parámetro a 2 para que evite la primera capa totalmente aleatoria y comience sobre una capa ya afectada por el prompt, sin embargo en imágenes realistas se deja en 1 lo cual no evitará ningún paso del ruido y comenzará sobre esa primera capa aleatoria.
Prompt, proceso de transformación de ruido y CFG Scale
El prompt son las instrucciones que le proporcionamos a la IA para generar nuestra imagen, en el caso del comienzo de la entrada, especifiqué «A cute fox girl» pero realmente se debe ser más especifico para alcanzar unos mejores resultados, por ahora sólo quiero presentar el concepto, publicaré una entrada dedicada solo al prompt más adelante.
Como vimos anteriormente, sin hacer uso de ninguna herramienta, este ruido será transformado principalmente de forma paralela en cada paso por 2 factores:
- La IA sin tomar en cuenta nuestro prompt tratará por su parte de ir dando forma al ruido de forma intuitiva para formar algo que considere coherente
- Por otra parte, generará otra capa de ruido que tratará de ir dando forma para que se aproxime a nuestro prompt
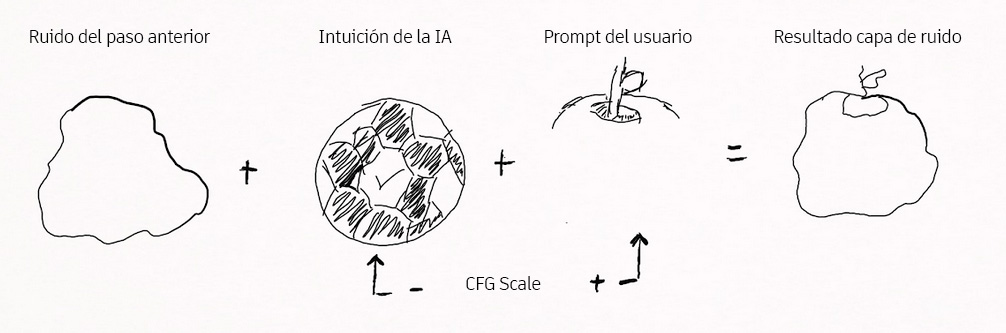
Una vez tiene ya generadas las 2 versiones de la capa de ruido, va a fusionarlas para generar la capa resultado del paso.
En el ejemplo anterior, el paso previo nos ha dejado un ruido de algo que parece ser un objeto circular, la IA por intuición cree que se trata de una pelota y lo redondea aún mas.
Por parte del prompt, especifica que es una manzana, por lo que el modelo sabe que las manzanas acaban con una endidura superior y el tallo.
Al combinar ambas capas de ruido, nos da como resultado una nueva capa de ruido aproximada a una esfera 3D gracias a la pelota, pero con la endidura y el tallo de una manzana, esta combinación es necesaria porque los modelos serían enormes a la hora de almacenar la información completa de cada objeto.
Pero sabe que tanto las pelotas como las manzanas comparten el rasgo común de ser redondeadas, por lo tanto con sólo almacenar las diferencias de la parte superior, es capaz de distinguir un objeto de otro sin almacenar mucha información.
El parámetro CFG Scale es el que le indica la importancia que tiene cada una, a mayor valor, mayor importancia le dará a la generada a través de nuestro prompt y menor importancia le dará a la que ha generado ella bajo su intuición.
Pero al igual que el número de pasos, exagerar con este valor no hará que nuestra imagen tome mas detalles de nuestro prompt, podemos variarlo ligeramente pero es importante encontrar un equilibrio y dejar que la IA tome su papel en el proceso también.
Con esto creo que podemos dar por finalizada la introducción a los conceptos básicos de Stable Diffusion y por tanto comenzar con los tutoriales en las siguientes publicaciones.
Puedes seguir la etiqueta Stable Diffusion para seguir todas las entradas relacionadas, además, también puedes encontrar mas publicaciones sobre otras IA en la categoría Inteligencia Artificial.